
Evaluation und Optimierung
Contents
Evaluation und Optimierung#
import pandas as pd
import plotly.express as px
import warnings
warnings.filterwarnings('ignore')
import plotly.io as pio
pio.templates.default = "plotly_white"
from plotly.offline import init_notebook_mode
init_notebook_mode() # To show plotly plots when notebook is exported to html
results = pd.read_csv("doc/Be_effective2_doku_2.csv", sep=";")
results["epochs"] = results["epoches"]
results[['model', 'img', 'batch', 'epochs', 'P', 'R', 'mAP50','mAP50:95']]
| model | img | batch | epochs | P | R | mAP50 | mAP50:95 | |
|---|---|---|---|---|---|---|---|---|
| 0 | model_1 | 1280 | 20 | 100 | 0.97300 | 0.36500 | 0.44500 | NaN |
| 1 | model_2 | 1280 | 20 | 300 | 0.94327 | 0.47249 | 0.54114 | NaN |
| 2 | model_3 | 1280 | 20 | 300 | 0.92900 | 0.53800 | 0.59800 | NaN |
| 3 | model_4 | 1920 | 20 | 300 | 0.90600 | 0.59700 | 0.39900 | NaN |
| 4 | model_5 | 1280 | 20 | 300 | 0.95100 | 0.73800 | 0.80300 | NaN |
| 5 | model_6 | 1280 | 30 | 300 | 0.93000 | 0.54900 | 0.59300 | NaN |
| 6 | model_7 | 1280 | 30 | 300 | 0.92000 | 0.51200 | 0.58100 | NaN |
| 7 | model_8 | 640 | 30 | 300 | 0.71700 | 0.60900 | 0.65100 | 0.43200 |
| 8 | model_9 | 640 | 30 | 200 | 0.86900 | 0.55600 | 0.67000 | 0.43500 |
| 9 | model_10 | 640 | 30 | 200 | 0.78500 | 0.55800 | 0.62600 | 0.38600 |
| 10 | model_11 | 640 | 30 | 300 | 0.81900 | 0.62900 | 0.70700 | 0.44700 |
| 11 | model_12 | 640 | 30 | 150 | 0.76000 | 0.68200 | 0.72800 | 0.46600 |
| 12 | model_13 | 640 | 30 | 150 | 0.84900 | 0.66800 | 0.74000 | 0.44200 |
| 13 | model_14 | 640 | 30 | 300 | 0.78700 | 0.61000 | 0.68900 | 0.43000 |
| 14 | model_15 | 640 | 30 | 300 | 0.88200 | 0.64500 | 0.72300 | 0.44500 |
| 15 | model_16 | 640 | 30 | 150 | 0.77000 | 0.60235 | 0.69525 | 0.43784 |
def compare_plot(dataframe, line_number_model_1, line_number_model_2, line_number_model_3 = 0, line_number_model_4 = 0):
df1 = dataframe[line_number_model_1 -1 : line_number_model_1][['P', 'R', 'mAP50']].transpose()
df1 = df1.reset_index()
df1['model']= "last benchmark"
df1 = df1.set_axis(['metric', 'value', 'model'], axis=1)
df2 = dataframe[line_number_model_2 -1 : line_number_model_2][['P', 'R', 'mAP50']].transpose()
df2['model']= "new model"
df2 = df2.reset_index()
df2 = df2.set_axis(['metric', 'value', 'model'], axis=1)
if(line_number_model_3 != 0):
df3 = dataframe[line_number_model_3 -1 : line_number_model_3][['P', 'R', 'mAP50']].transpose()
df3['model']= "new model 2"
df3 = df3.reset_index()
df3 = df3.set_axis(['metric', 'value', 'model'], axis=1)
if(line_number_model_4 != 0):
df4 = dataframe[line_number_model_4 -1 : line_number_model_4][['P', 'R', 'mAP50']].transpose()
df4['model']= "new model 3"
df4 = df4.reset_index()
df4 = df4.set_axis(['metric', 'value', 'model'], axis=1)
horizontal_concat = pd.concat([df1, df2])
if(line_number_model_3 != 0):
horizontal_concat = pd.concat([horizontal_concat, df3])
if(line_number_model_4 != 0):
horizontal_concat = pd.concat([horizontal_concat, df4])
fig = px.line_polar(horizontal_concat, r="value", theta="metric", color="model", line_close=True,)
fig.show()
def print_results(name, df, line):
print(f"Die Resultate des {name} sind:")
print(f"Precision: {df['P'][line]}")
print(f"Recall: {df['R'][line]}")
print(f"MaP50: {df['mAP50'][line]}")
Übersicht über Modelle#
Nach der explorativen Datenanalyse und dem Feature Engineering werden in diesem Abschnitt Modelle analog zum Tarnkappenbomber erstellt. Zur Ermittlung des besten Modells werden mehre Optimierungsschritt durchgeführt. Ergebniss waren rund 30 Modell, welche in Colab trainiert wurden. Die 13 zielführendesten Modelle werden in diesem Abschnitt erläutert. Der nachfolgende Plot zeigt die Map50-Werte der einzelnen Modelle, welchen wir als Key Performance Indicator (KPI) verwenden.
Die aufgeführten Modell stellen die Arbeitsergebnisse im zeitlichen Verlauf dar. Ziel des jeweiligen Modells ist den aktuellen Vorgänger-Benchmark zu übertreffen. In den nachfolgenden Kapitel werden diese Optimierungsschritte erläutert.
fig = px.bar(results, x="model", y="mAP50")
fig.show()
Fig. 29 Eigene Darstellung: Modellvergleich zum mAP50#
Basismodell: Modell 1#
Als Hilfestellung für die Erstellung eines Basismodell für ein benutzerdefiniertes Data Set ist auf der Seite von Ultralytics ein Guide vorgehalten [Jocher, 2022]. Wie bereits beim Tarnkappenbomber erläutert, werden Standardwerte zur Erstellung des Basismodell genutzt. Abweichend von den Standardwerten wird für den ersten Versuch eine geringer Anzahl an Epoche gewählt und entsprechen der Empfehlung für kleine Objekt eine größere Image-Size. Es handelt sich um folgende Parameter:
!python train.py --img 1280 --batch 20 --epochs 100 --data planes_and_helicopters.yaml --weights yolov5s.pt
print_results("Basisszenario", results, 1)
Die Resultate des Basisszenario sind:
Precision: 0.94327
Recall: 0.47249
MaP50: 0.54114
Das Basismodell ist der Ausgangspunkt für die folgenden Modellierungen.
Verbesserung: Modell 1 zu Modell 2#
Das zweite Modell wird mit 300 statts 100 Epochen trainiert.
compare_plot(results, 1, 2)
Fig. 30 Eigene Darstellung: Modellvergleich Result 1#
In der Grafik wird eine Verbesserung des mAP50 deutlich. Damit ist das Modell 2 Ausgangspunkt für weitere Verbesserungen.
Verbesserung: Modell 2 zu Modell 3#
Bisher folgten wir der Empfehlung von bis zu 10 % Background-Bilder für Training und Validation, welche im Dataframe mit „few“ markiertet sind. Bei der Feature Exploration wurde eine geringe Anzahl an Bildern erkannt. Es wird vermutet, dass durch die geringe Anzahl an Bildern - nicht Instanzen - zu wenig Background gelernt werden kann, weshalb dieser nochmal deutlich erhöht wird.
compare_plot(results,2,3)
Fig. 31 Eigene Darstellung: Modellvergleich Result 2#
Confusion Matrix Modell 3
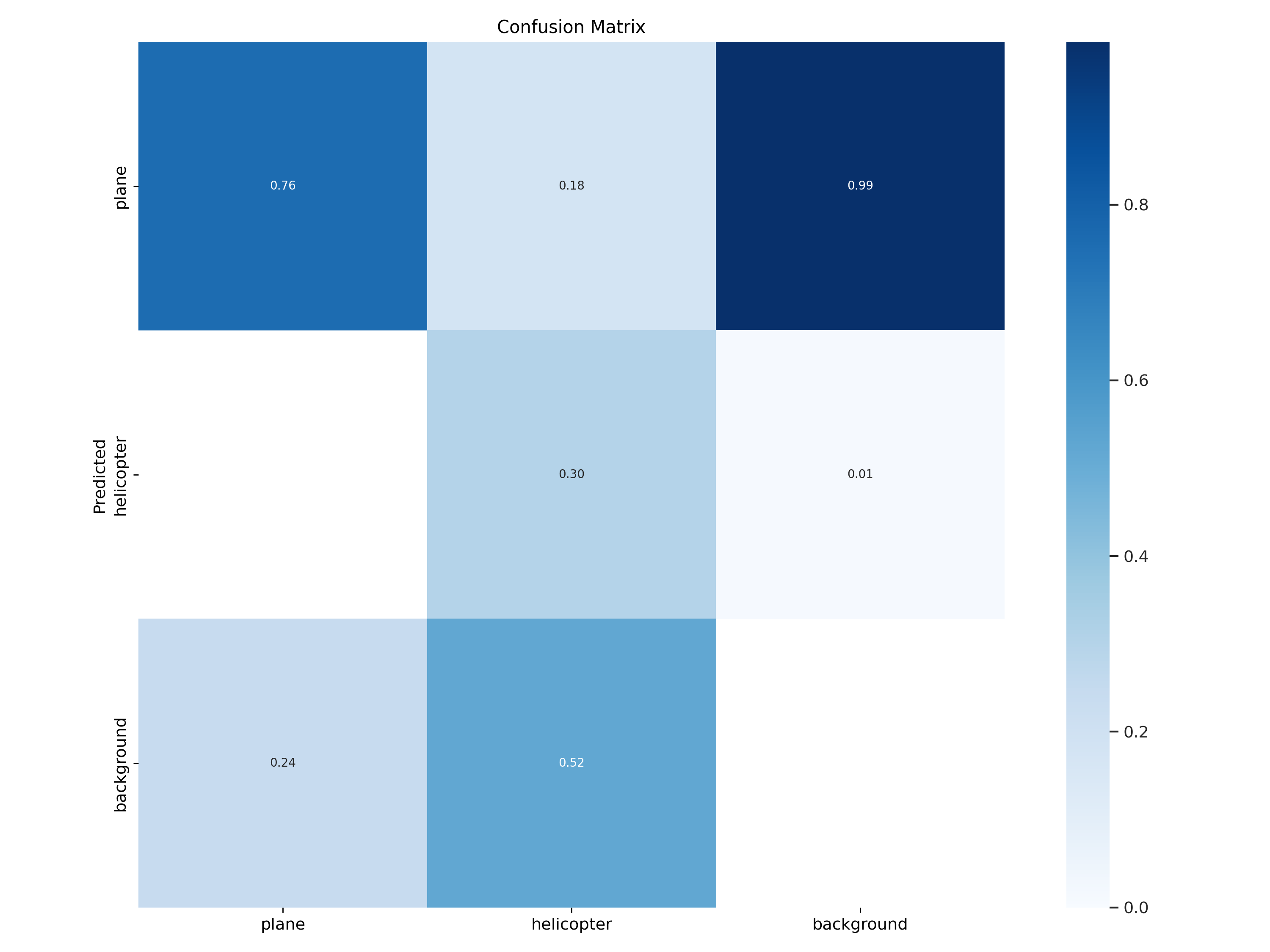
Fig. 32 Modell 3 Confusion Matrix#
Auffallend bei der Betrachtung der Confusion Matrix ist die geringe Anzahl an True Positiv Detektion von Helikoptern und eine hohe Anzahl von False Positiv bei den Planes. Zweiteres ist ein ähnliches „Background“-Problem wie im Tarnkappenbomber-Exkurs.
Durch die weiteren Background-Bilder konnte der mAP50 leicht gesteigert werden. Aus diesem Grund werden diese für die nachfolgenden Modelle weiter genutzt. Ein Grund für die geringer Steigerung des mAP50 könnte sein, dass die Background-Bilder nicht immer geeignet sind. Die enthalten auch Häfen, Seen und Tennisplätze, welche keine Ähnlichkeit zu Rollfelder aufweisen.
Aus den bisherigen niedrigen Recalls lässt sich auch auch auf viele Type 2 Error Detections schließen. D.h. die Groundtruth wird nicht erkannt. Vor diesem Hintergrund wird im folgenden Versucht die Einflussfaktoren so anzupassen, dass das Erkennen von Objekten im Training leichter fällt.
Verbesserung: Modell 3 zu Modell 8#
In den folgenden Modellen werden die Ergebnisse des Health Checks mit einbzogen, um das Modell zu optimieren. Diese können wie folgt zusammengefasst werden:
sehr große nicht quadratische Bilder mit kleinen Objekten
deutlich weniger Helikopter-Instanzen im Vergleich zu Plane-Instanzen
Wie bereits beim Tarnkappenbomber erläutert, performen die Modelle mit einer Image Size von 640 Pixel am besten. Dies wird auch von der YOLOv5-Dokumentation empfohlen. Im Basismodell ist bereits die größere Imagesize von 1280 Pixel für kleine Objekte berücksichtigt. Im Rückblick Health Check wird deutlich, dass die Bilddaten trotzdem sehr stark eingeschrumpft werden. Aus diesem Grund wird mit Modell 4 getestet, ob die ImageSize 1920 Pixel zu einem besseren Ergebnissen führen könnte.
print_results("Modell 4", results, 3)
Die Resultate des Modell 4 sind:
Precision: 0.906
Recall: 0.597
MaP50: 0.399
Der bereits im ersten Plot dargestellte Einbruch beim mAP50 von Modell 3 auf Modell 4 zeigt bereits ein deutlich schlechteres Ergebniss. Aus diesem Grund wird die weitere Erhöhung der Imagesize nicht weiterverfolgt.
Ziel von Modell 5 ist es zu überprüfen inwieweit ein Modell nur mit der Klasse “Planes” besser performt. Die Vermutung liegt nahe, da zum einen der Health Check auf die geringe Anzahl Helikopter-Instanzen hinweist und zum anderen die Confusion Matrix des Modells 3 eine geringe Anzahl an True Positiv Detektionen von Helikoptern aufweist.
compare_plot(results,3,5)
Fig. 33 Eigene Darstellung: Modellvergleich Result 3#
Trotz der deutlich besseren Performance (siehe Plot) wird der Ansatz nicht weiterverfolgt, da Ziel des UseCases ist alle Arten von Flugobjekten zu erkennen. Es wird jedoch deutlich, dass das Gesamtergebniss stark von geringen Helikopter Instanzen beeinflusst wird.
In Modell 6 und Modell 7 wird daher die Anzahl der Helikopterinstanzen schrittweise erhöht. Dies erfolgt mit Image-Augmentation, außerhalb von Yolo. D.h.die Bilddateien, welche eine Helikopterinstanz enthalten, werden um eine beliebigen Grad rotiert - wie im Abschnitt Data Enrichment beschrieben.
Da in fast allen Helikopter-Bilddateien auch Flugzeuge abgebildet sind, wird die Anzahl der Flugzeug-Instanzen mit erhöht. Das Ungleichgewicht zwischen den Instanzen kann also nicht verringert werden, aber zumindest die Anzahl der Helikopter-Instanzen erhöht. Im Vergleich zu Modell 3 (siehe nachfolgende Grafik) ergibt sich jedoch keine Performance-Verbesserung.
Eine weitere Recherche zu Helikopter-Bildern, um die Anzahl der Instanzen zu erhöhen, verlief erfolglos. Stattdessen wurde das in der Einleitung vorgestellte Airbus-Produkt entdeckt.
fig = px.bar(results.iloc[[2,5,6],:], x="model", y="mAP50")
fig.show()
Fig. 34 Eigene Darstellung: mAP50 zu Modell 3, 6 und 7#
Neben der Erhöhung der Auflösung ist eine weitere Taktik um mit kleinen Objekten umzugehen, dass “kachlen” (englisch tiling) der Bilder. Dabei wird das Bild in nicht-überlappende kleinere Quadrate geteilt. Das hat zum einen den Vorteil, dass die Objekt in den kleineren Bildern vergrößert werden und zum anderen kann die Tile-Größe entsprechend der optimalen Größe für YOLOv5 gewählt werden. [Solawetz, 2020]
Für das Tiling wird, wie beim Rotieren, ein Github-Repo genutzt, welches nicht nur die Bilder sondern auch die zughörigen Label zerlegt. Es werden Kacheln in der Größe 640x640 Pixel (siehe Kapitel Data Enrichment) erstellt. Die zerlegten Bilder werden für das Training von Modell 8 verwendet.
Das Tiling führte zu einem großen Performance-Boost in Modell 8. Im Vergleich zum bisherigen Benchmark Modell 3 steigt der mAP50 von 0.598 auf 0.651. Bei diesem mAP50 brach das Training in Epoche 111 von 300 ab. Dies ist Anlass von einem Vergleich der Confusion Matrizen von Modell 3 und 8.
Die Gegenüberstellung der Confusion Matrizen unterstützt die Aussage zum Performance-Boost beim mAP50. Der Anteil an True Positive Predictions hat sich für Flugzeuge und Helikopter deutlich verbessert. In den weitern Schritten wird versucht die übrige Fehlklassifikation zu reduzieren.
Confusion Matrix Model 8
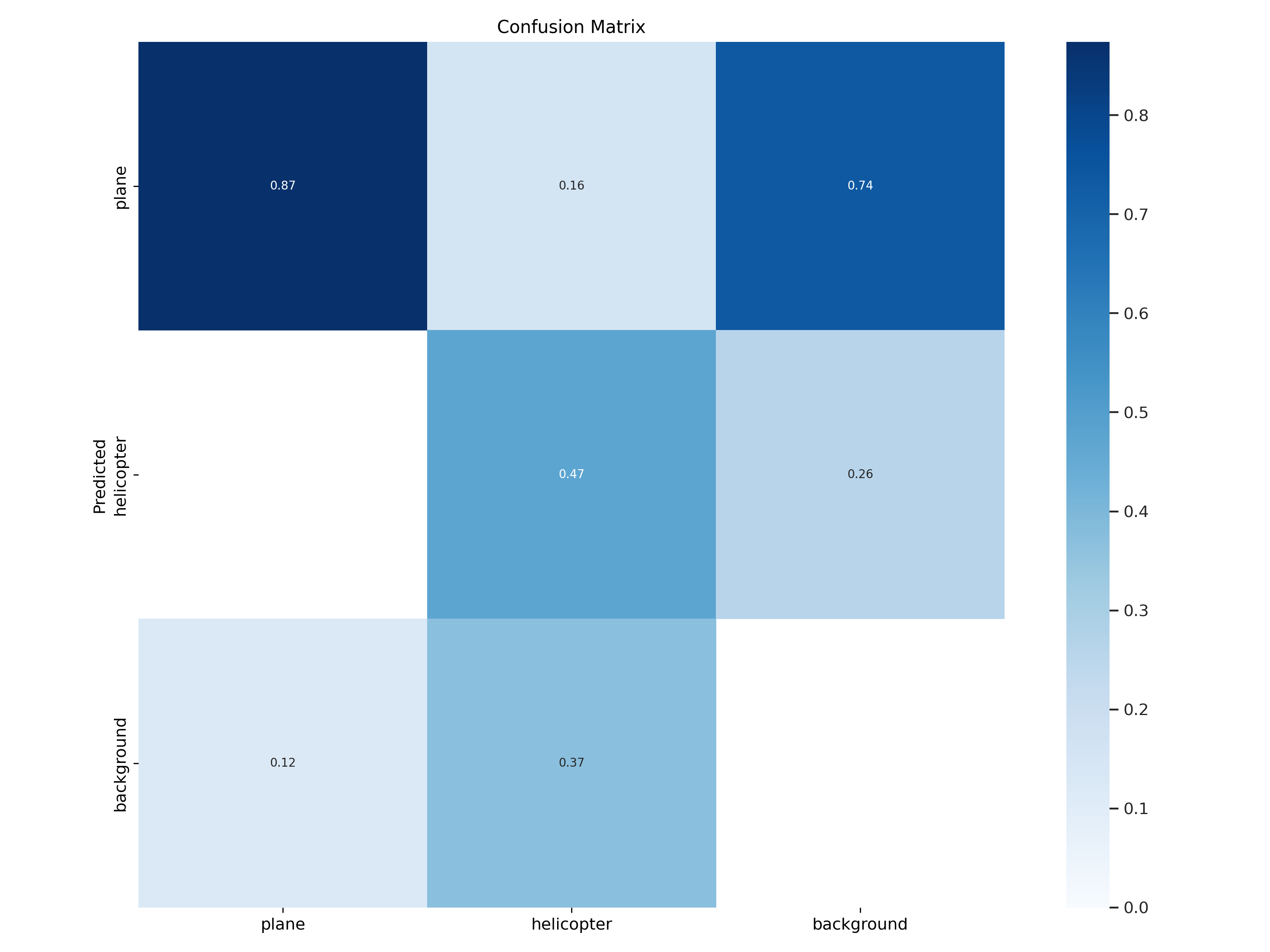
Fig. 35 Modell 8 Confusion Matrix#
Verbesserung: Modell 8 zu Modell 9#
Wegen des frühzeitigen Trainingsabbruchs bei Modell 8 wird in Modell 9 auf die Gewichte von Modell 8 aufgebaut und mit anderen Hyperparametern trainiert. Dies erfolgt mit der beim Tarnkappenbomber vorgestellten hyp.VOC.YAML-Datei, welche u.A. eine geringere Learning Rate verwendet.
Durch die leicht Steigerung des mAPs von Modell8 zu Modell 9, wurde in Modell 10 nochmal der Backbone-Freeze auf die Modell-8-Struktur mit anschließender Hyperparameteroptimierung (hyp.VOC.YAML) durchgeführt. Jedoch ohne Erfolg.
Verbesserung: Modell 9 zu Modell 13#
Da das mAP50-Wachstum bisher relativ gering war, wird nachfolgend die Anzahl an Layern und Channels vergrößert. Dazu wird mit den Modellen M,L und XL von YOLOv5 gearbeitet. In der Projektarbeit handelt es sich dabei um Modell 11, Modell 12 und Modell 13.
compare_plot(results,9,11,12,13)
Fig. 36 Eigene Darstellung: Modellvergleich Result 4#
Von Modell 11 zu Modell 13 lässt sich eine Performance-Steigerung im mAP50 beobachten. Damit zeigt sich, dass ein größeres Modell wesentlich bessere Ergebnisse hervorbringt.
print_results("Modell 13", results, 12)
Die Resultate des Modell 13 sind:
Precision: 0.849
Recall: 0.668
MaP50: 0.74
Confusion Matrix Modell 13
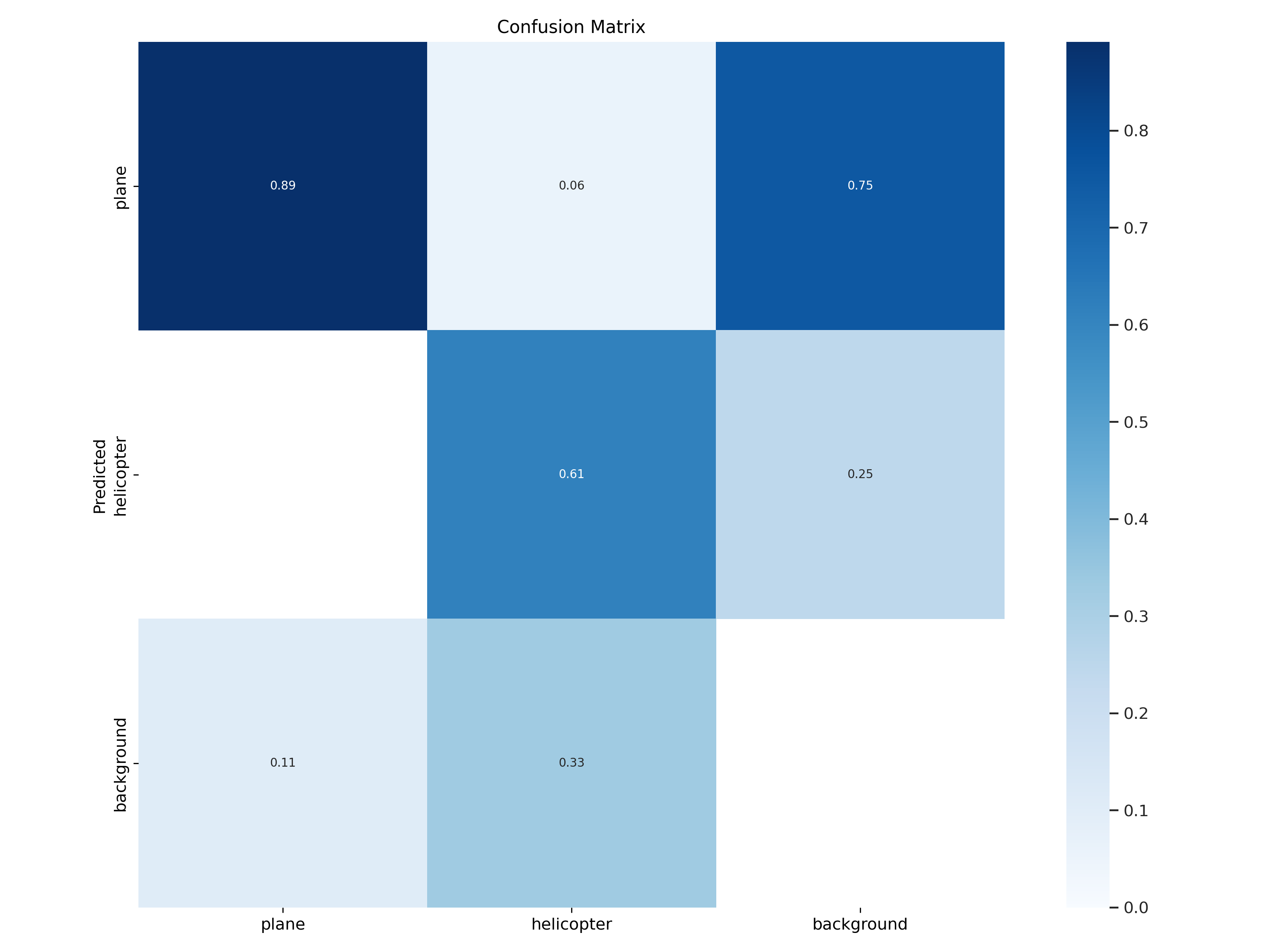
Fig. 37 Confusion Matrix Modell 13#
In der Confusion Matrix ist zu erkennen, dass 89% aller Flugzeug und 61% aller Helikopter korrekt detektiert werden. Verwechselungnen zwischen Helikoptern und Flugzeugen kommen so gut wie nicht vor. Jedoch gibt es weiterhin False-Positive-Erkennung.
Results Modell 13
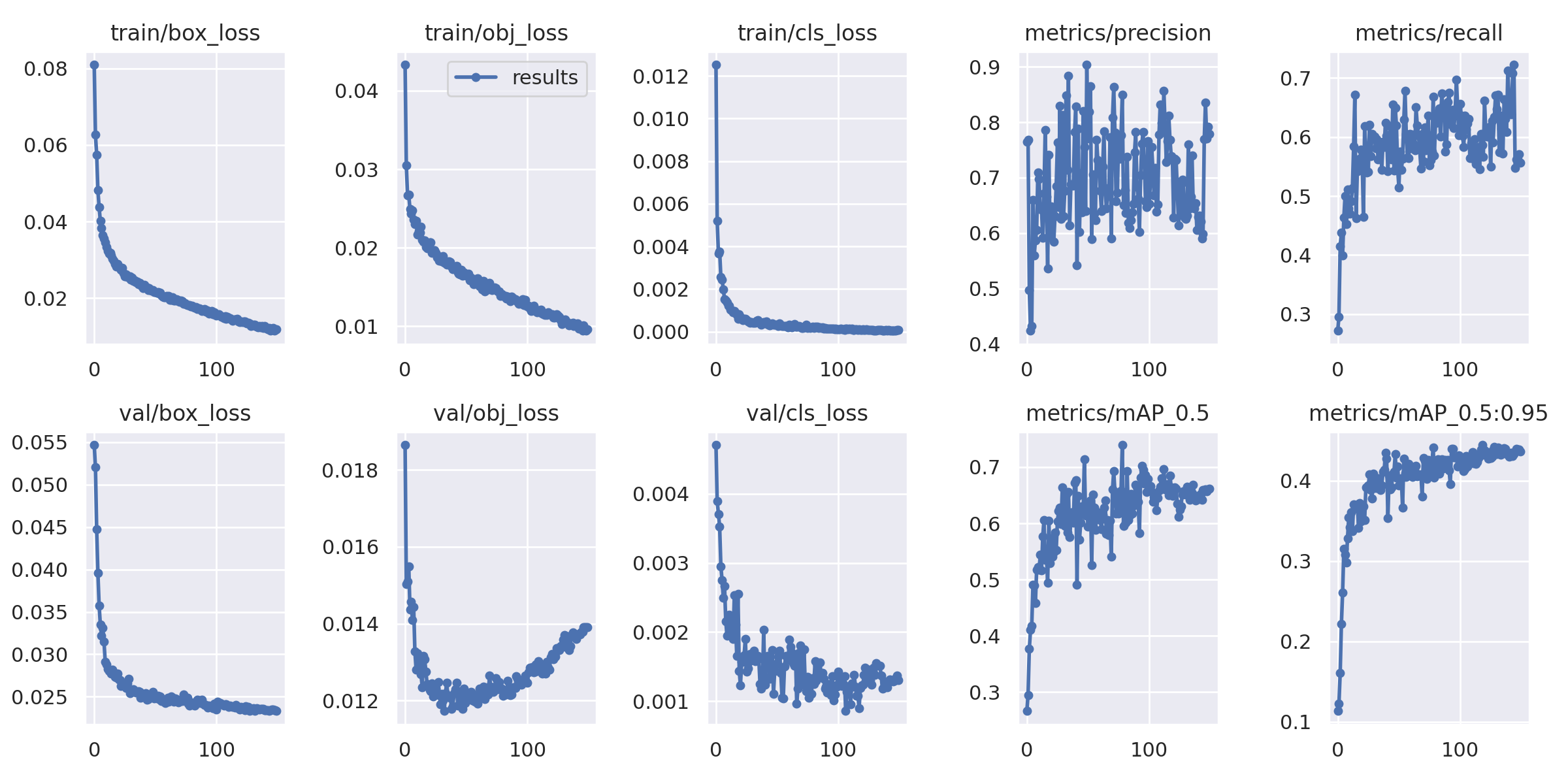
Fig. 38 Results Modell 13#
Der class loss sinkt sowohl beim Training, wie bei der Validierung stetig. Das unterstreicht die geringe Rate an Verwechselungen zwischen Helikoptern und Flugzeugen. Gleiches gilt für den box loss. Bei dem object loss ist bei der Validierung ein Anstieg zu verzeichnen. Die kann sich auf die False-Erkennungen beziehen. Der mAP50:95 steigt sehr stetig an während die Metriken Precision, Recall und mAP50 ein sprunghaftes, aber anwachsendes Verhalten aufweisen.
Weiterführung: Modell 13 zu Modell 16#
Nachdem Modell 13 als bestes Modell hervorgeht, das komplizierteste jedoch nicht immer das sinnvollste Modell ist, wird nochmal geprüft, ob das M-Modell mit Hyperparameteroptimierung über die hyp.VOC.yaml, besser wird. Dies erfolgt in Modell 14. Eine letzte Anwendung von hyp.VOC in Modell 15 soll sicherstellen, dass Modell 13 nicht weiter verbessert werden kann.
In Modell 16 wird eine weitere Methode zur Hyperparameteroptiermierung angewendet. Über den evolve-Parameter wird das komplette Training für mehrer Generationen wiederholt. Lt. Jocher [2020] werden 300 Generationen empfohlen. Wegen der Colab-Laufzeitbegrenzung werden nur 10 Generationen durchlaufen.
Für das Deployment wird Modell 13 als bestes Modell genutzt.