
YOLOv5 - Grundlagen
Contents
YOLOv5 - Grundlagen#
Object Detection vs Image Classification#
Die Objekterkennung unterscheidet sich von der Bilderkennung. Für das Projektziel ist die Bilderkennung ungeeignet, weil sie nur ein Objekt erkennen und dieses maximal lokalisieren kann.
Stattdessen wird ein Methode benötigt, welches multiple Objekte erkennt und klassifiziert. Für diese Anwendung gibt es ebenfalls unterschiedliche Möglichkeiten wie RCNN oder YOLO. Für diese Arbeit wurde YOLOv5 gewählt, weil dieses verbreitet ist und zum Abschluss des Deployments ein Pandas-Dataframe für den Use Case ermöglicht.
Das nachstehende Bild stellt die Unterschiede zwischen Methoden zur Bildklassifikation dar. Für diese Arbeit wird eine Object Detection für multiple Objects gebraucht, welche im dritten Bild von Links dargestellt wird.
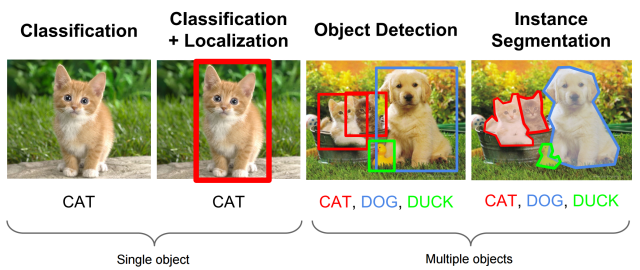
Fig. 1 Methoden zur Bildklassifikation [Akyon, 2021]#
Modelle / Vortrainierte Gewichte#
YOLOv5 bietet verschiedene Grundmodelle für Deep Learning Neural Networks. Diese Modelle werden in einer YAML-Datei bereitgestellt und können über den –cfg Parameter aufgerufen werden.
Die Modelle bestehen aus Backbone und Head. Die Fachliteratur unterscheidet zusätzlich einen Neck, welcher in der YAML-Datei bei YOLOv5 im Head dargestellt wird. Der Backbone kann als Feature Extractor und der Head als Classifier verstanden werden.
Alternativ zur config werden pretrained Weights bereitgestellt, welche beispielsweise auf dem COCO Datensatz trainiert wurden.
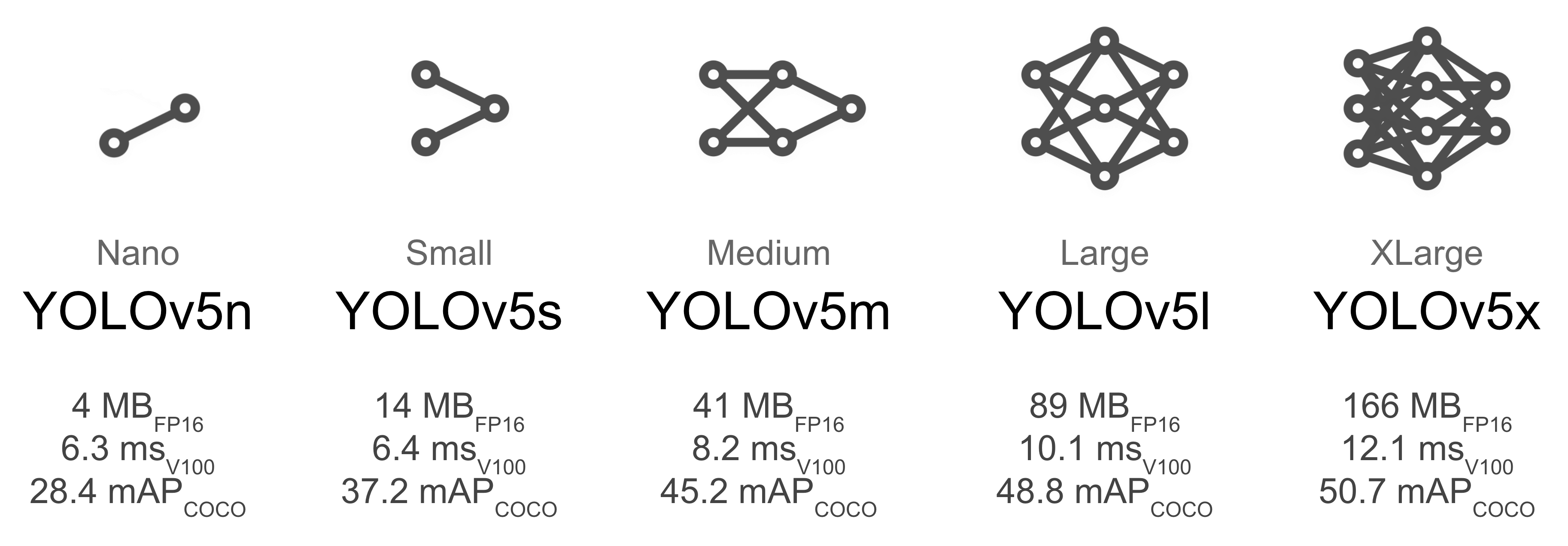
Fig. 2 YOLOv5-Modelle [Jocher, 2022]#
In der nachfolgenden YAML-Datei des S-Modells werden folgende Kategorien abgebildet. Die Struktur ist für alle Modelle identisch.
nc
depth_multiple
width_multiple
anchors
Es ist zu erkennen, dass Backbone und Head unterschiedliche Layer enthalten. Ferner werden Standardwerte für Anchorboxen gesetzt und Grenzen für Tiefe / Weite des Netz.
Der Parameter nc kann in der Datei angepasst werden oder wird über die Anzahl der Labels automatisch korrigiert.
Die Parameter depth_multiple und width_multiple verändern die Tiefe und Breite des Modells. Diese Werte werden verwendet um einen Unterschied zwischen den Modellen zu erzeugen. D.h. alle Modelle verwenden die gleiche Layer-Architektur in unterschiedlicher Breite und Tiefe.
Anchors meint Listen von Anchor-Boxen, welche zur Prediction der Bounding Box benötigt werden. In YOLOv5 werden die Anchor-Boxen mit automatischer k-means Analyse vom Traininsdaten-Set erlernt, weshalb die manuelle Anpassung optional ist. Generell gilt, dass diese Anchor-Boxen so gewählt werden müssen, dass sie zu den Daten passen. Beispielsweise wird für ein schmalles längliches Objekt eine andere Box benötigt als für ein gestauchtes breites Objekt.
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Modell-Architektur#
Layer#
In der oben gezeigten Modell-YAML-Datei werden folgende Layer verwendet.
Convolution
C3
SPPF
Upsample
Concat
Diese beziehen sich auf Methoden, welche wiederum mit den PyTorch-Funktionen und Methoden arbeiten. Nachfolgend wird exemplarisch die Klasse Conv abgebildet. Darin werden die PyTorchFunktionen Conv2d und BatchNorm2d angewendet.
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
Convolutional Layer#
YOLOv5 verwendet als ersten Layer einen Convolution Layer mit [-1, 1, Conv, [64, 6, 2, 2]]. Der Eintrag ist wie folgt zu lesen.
Reihenfolge im Modell = -1
Anzahl Wiederholungen im Layer = 1
Layer-Art = Conv bzw. Convolutional
Layer-Parameter = [out_channel, kernel_size, stride, padding]
Ein Convolutional Layer extrahiert Features aus einem Bild. Das Ergebnis wird Feature Map genannt.
Zu Beginn wird das Rohdaten-Bild mit drei Kanälen (Rot, Grün und Blau) in das Training übergeben. Die Anzahl der Känale von Feature Maps ist wesentlich größer. So sollen bei dem Output des ersten Layers 64 Kanäle erzeugt werden.
Die Größe der Output-Feature Map wird wie folgt berechnet.
\( Outputsize = (Inputsize - Kernelsize + 2 * Padding) / Stride + 1 \)
Für die Layer-Parameter und ein Inputimage mit 640x640 px ergibt sich somit folgende Outputsize.
\( 320 = (640 - 6 + 2 * 2) / 2 + 1 \)
Zusätzlich wird die Channel-Anzahl von 64 auf 32 halbiert, weil im S-Modell der width-multiple den Out-channel halbiert.
Die FeatureMap hat somit die Paremeter:
320x320
32 Channel
CSP Bottleneck Layer#
Bottleneck Layer werden dazu verwendet um die wachsende Anzahl an Feature Map Channels zu reduzieren und relavante Feature Maps zu extrahieren.
Die C3 Layer sind “simplified CSP modules with 3 convolutions [Jocher, 2022]”, welche das Verhältnis von Input zu Output Channels halbieren.
SPPF#
Der Einsatz von Spatial Pyramind Pooling ermöglicht unterschiedliche Image-Size für Input Images, welche zuvor für den Fully Connected Layer fixiert werden musste.
Der SPPF ist ein für YOLOv5 geschriebenes Modul, welches zu den gleichen Ergebnissen wie SPP kommt. Der Output des SPPF Layers wird als Input für einen Convolutional Layer verwendet, weshalb die ursprüngliche Image Size Fixierung nicht der Einsatzgrund ist. Lt. Issue-Diskussion heißt es, dass der SPPF Layer lediglich zu besseren Ergebnissen bei der Detection führt. [Jocher, 2021]
Upsample#
Die ist eine reine Funktion von Pytorch. Durch das Upsampling wird die Bildgröße, über den scale_factor=2, verdoppelt. Dazu wird der Modus “nearest” verwendet.
Concat#
Bei der von PyTorch zur Verfügung gestellten Concat-Funktion werden die Tensoren verbunden. In diesem Fall über die Dimension Channels.
Working Directory#
Für die Arbeit mit YOLOv5 müssen die python-Dateien über Terminal-Eingaben aufgerufen werden. Dafür wird das Working Directory hier vorgestellt. Dabei wird die Beschreibung auf verwendete Strukturen des YOLOv5 Repository beschränkt.
Im Ordner data liegen zwei Arten von YAML-Dateien. Die YAML-Datei welche Labels und Bilder zusammenführt sowie die YAML-Datei mit Hyperparametern. YOLOv5 verwendet Standarddateien, wenn kein Pfad übergeben wird.
Diese YAML-Dateien sind nicht zu verwechseln mit den oben beschriebenen Modell-YAML-Dateien.
Im unten dargestellten Working Directory wird die planes-and-helicopters.yaml Datei verwendet, um Bilddateien und Labeldateien zusammenzuführen. Grundsätzlich geht YOLOv5 davon aus, dass diese Dateien in einem Ordner auf der Ebene des Repositories abgelegt sind. Diese unterscheiden zwischen Trainings- und Validierungsdaten. Die Labels sind in Textdateien gespeichert und haben den Dateinamen der Bilddatei.
Der Ordner runs enthält die Ergebnisse aus Training, Validation und Detection. Mit Detection sind die Ergebnisse der Inference (Modellanwendung) gemeint.
Für die jeweilige Aufgabe Training, Validation oder Detection gibt es je ein py-File, welches mit der gegebenen Struktur arbeitet. Daher muss mit YOLOv5 innerhalb des Repository gearbeitet werden.
Ablage Bilder und Label
|
+-- images
| +-- train
| | |
| | +-- exampleIMG001.png
| |
| +-- validation
|
|
+-- labels
| +-- train
| | |
| | +-- exampleIMG001.txt
| |
| +-- validation
|
|
yolov5 Repository
|
+-- data
| +-- hyps
| | |
| | +-- hyp.scratch-low.yaml
| | +-- hyp.VOC.yaml
| |
| +-- planes-and-helicopters.yaml
|
+-- models
| |
| +-- yolov5n.yaml
| +-- yolov5s.yaml
| +-- yolov5m.yaml
| +-- yolov5l.yaml
| +-- yolov5x.yaml
|
+-- runs
| +-- detect
| | |
| | +-- exp
| | |
| | +-- image with detection result
| |
| +-- train
| | |
| | +-- exp
| | |
| | +--weights
| | | |
| | | +-- best.pt
| | | +-- last.pt
| | |
| | +-- image files with metrics, confusion matrix, etc.
| |
| +-- val
| | |
| | +-- exp/run
| | |
| | +-- image files with confustion matrix and metrics
|
+-- detect.py
+-- train.py
+-- val.py